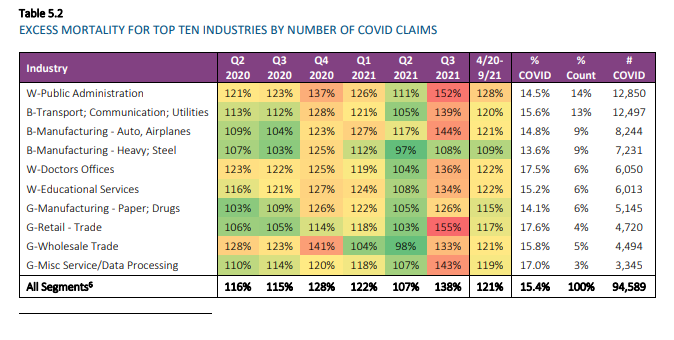
Table 5.2 shows more detailed industry results for the top ten industry segments by number of COVID claims. Most of these industries were in the top ten for the July 2021 report as well. As we now have more quarters with more complete results, both the A/E ratios for April 2020 through September 2021, as well as the COVID claims as a percentage of baseline claims, showed greater consistency across industries than in the previous report. Public Administration continues to be a key driver of high A/E ratios for the White Collar category. Doctors (Healthcare, also White Collar), Retail Trade (Grey Collar), and Misc. Services (Grey Collar) have the highest COVID claims as a percentage of baseline claims. Heavy Steel Manufacturing (Blue Collar) has a much lower A/E ratio than the other top 10 industries. In the table below, “B,” “W,” and “G” refer to Blue Collar, White Collar, and Grey Collar, respectively.
It should be noted that the high A/E ratios for Public Administration are driven by experience in the Executive, Legislative, and General Government segment (Standard Industry Classification [SIC] codes 9100-9199). This segment does not include police and fire and represents over 85% of claims in the broader Public Administration segment.
Video:
Publication Date: January 2022
Publication Site: Society of Actuaries Research Institute
OpenAI inside Excel? How can you use an API key to connect to an AI model from Excel? This video shows you how. You can download the files from the GitHub link above. Wouldn’t it be great to have a search box in Excel you can use to ask any question? Like to create dummy data, create a formula or ask about the cast of the The Sopranos. And then artificial intelligence provides the information directly in Excel – without any copy and pasting! In this video you’ll learn how to setup an API connection from Microsoft Excel to Open AI’s ChatGPT (GPT-3) by using Office Scripts. As a bonus I’ll show you how you can parse the result if the answer from GPT-3 is in more than 1 line. This makes it easier to use the information in Excel.
I’m often looking at distributions, and wanting to communicate something about how those distributions change over time, or how distributions compare. Often, I have to simply pick out key percentiles in those distributions, or key aspects, such as mean and standard deviation.
But why not graph all the points in one’s sample directly, if one has them?
In a groundbreaking TED-style talk, Dominic Lee, ACAS takes the audience on a multisensory journey beyond the boundaries of traditional insurance. He presents a framework for the actuarial profession to step into the future and claim its rightful place as a dominant force in the world of risk: Reimagine, Embrace and Explore.
The insurance industry is unique in that the cost of its products—insurance policies—is unknown at the time of sale. Insurers calculate the price of their policies with “risk-based rating,” wherein risk factors known to be correlated with the probability of future loss are incorporated into premium calculations. One of these risk factors employed in the rating process for personal automobile and homeowner’s insurance is a credit-based insurance score.
Credit-based insurance scores draw on some elements of the insurance buyer’s credit history. Actuaries have found this score to be strongly correlated with the potential for an insurance claim. The use of credit-based insurance scores by insurers has generated controversy, as some consumer organizations claim incorporating such scores into rating models is inherently discriminatory. R Street’s webinar explores the facts and the history of this issue with two of the most knowledgeable experts on the topic.
Featuring:
[Moderator] Jerry Theodorou, Director, Finance, Insurance & Trade Program, R Street Institute Roosevelt Mosley, Principal and Consulting Actuary, Pinnacle Actuarial Services Mory Katz, Legacy Practice Leader, BMS Group
R Street Institute is a nonprofit, nonpartisan, public policy research organization. Our mission is to engage in policy research and outreach to promote free markets and limited, effective government.
We believe free markets work better than the alternatives. We also recognize that the legislative process calls for practical responses to current problems. To that end, our motto is “Free markets. Real solutions.”
We offer research and analysis that advance the goals of a more market-oriented society and an effective, efficient government, with the full realization that progress on the ground tends to be made one inch at a time. In other words, we look for free-market victories on the margin.
R Street Institute Director of Finance, Insurance and Trade Jerry Theodorou presents on social inflation and his latest policy study to the Business Insurance World Captive Forum in Miami in February.
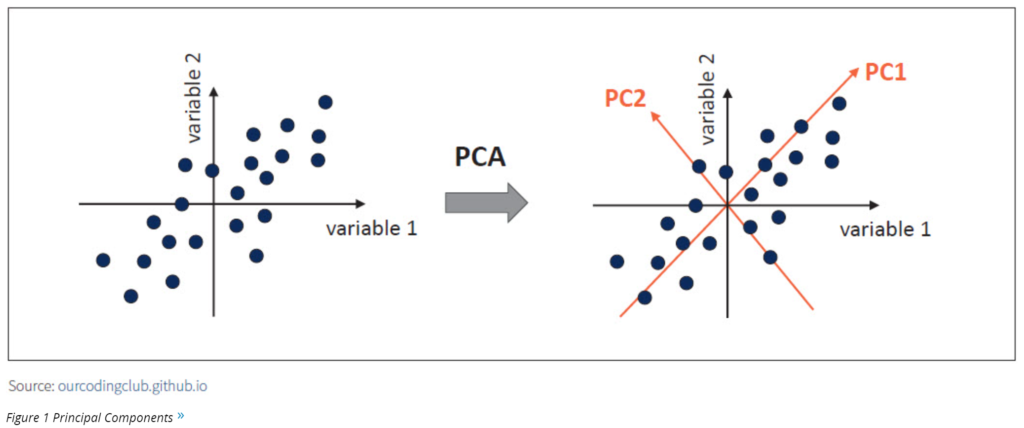
In simple words, PCA is a method of extracting important variables (in the form of components) from a large set of variables available in a data set. PCA is a type of unsupervised linear transformation where we take a dataset with too many variables and untangle the original variables into a smaller set of variables, which we called “principal components.” It is especially useful when dealing with three or higher dimensional data. It enables the analysts to explain the variability of that dataset using fewer variables.
The inaugural coffee chat of my YouTube channel features two research scholars from scientific community who shared their perspectives on how data plays a crucial role in research area.
By watching this video you will gather information on the following topics:
a) the importance of data in scientific research,
b) valuable insights about the data handling practices in research areas related to molecular biology, genetics, organic chemistry, radiology and biomedical imaging,
c) future of AI and machine learning in scientific research.
Author(s):
Efrosini Tsouko, PhD from Baylor College of Medicine; Mausam Kalita, PhD from Stanford University; Soumava Dey
Publication Date: 26 Sept 2021
Publication Site: Data Science with Sam at YouTube
A look at the pattern of weekly deaths, all causes, for the entire United States through the beginning of September 2021, as well as: California Texas New York (minus NYC) New York City Pennsylvania Illinois CDC excess mortality dashboard: https://www.cdc.gov/nchs/nvss/vsrr/co…
Have you ever built a perfect financial model without any errors? Thought not! And for that reason, all good modellers know they need to include some error checks. But what is not as clear is how many error checks you should have, when you should include them and what form they should take. Excel “helpfully” provided us with functions like ISERR, ISERROR and IFERROR but as you progress your modelling journey you should learn to avoid these functions. Plus, you also learn the sad truth that Excel can’t even do basic maths sometimes! Join us to hear from financial modelling specialist Andrew Berg, who has spent years building models, and so happily admits he has probably already made most of the mistakes you haven’t yet had a chance to! The good news is that he is willing to share the tips he has learned about the right types of error checks to add to your models so you don’t have to learn the hard way. ★Download the resources here ► https://plumsolutions.com.au/virtual-… ★Register for more meetups like this ► https://plumsolutions.com.au/meetup/ ★Connect with Andrew on Linkedin ► https://www.linkedin.com/in/andrew-be…