Link: https://www.soa.org/sections/investment/investment-newsletter/2022/february/rr-2022-02-shang/
Graphic:
Excerpt:
This article summarizes key points from the recently published research paper “Deep Learning for Liability-Driven Investment,” which was sponsored by the Committee on Finance Research of the Society of Actuaries. The paper applies reinforcement learning and deep learning techniques to liability-driven investment (LDI). The full paper is available at https://www.soa.org/globalassets/assets/files/resources/research-report/2021/liability-driven-investment.pdf.
LDI is a key investment approach adopted by insurance companies and defined benefit (DB) pension funds. However, the complex structure of the liability portfolio and the volatile nature of capital markets make strategic asset allocation very challenging. On one hand, the optimization of a dynamic asset allocation strategy is difficult to achieve with dynamic programming, whose assumption as to liability evolution is often too simplified. On the other hand, using a grid-searching approach to find the best asset allocation or path to such an allocation is too computationally intensive, even if one restricts the choices to just a few asset classes.
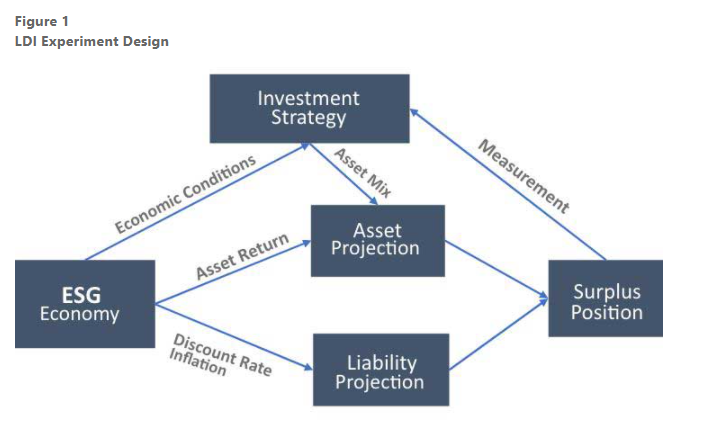
Artificial intelligence is a promising approach for addressing these challenges. Using deep learning models and reinforcement learning (RL) to construct a framework for learning the optimal dynamic strategic asset allocation plan for LDI, one can design a stochastic experimental framework of the economic system as shown in Figure 1. In this framework, the program can identify appropriate strategy candidates by testing varying asset allocation strategies over time.
Author(s): Kailan Shang
Publication Date: February 2022
Publication Site: Risks & Rewards, SOA