Link: https://onlinelibrary.wiley.com/doi/full/10.1111/eci.13998
Graphic:
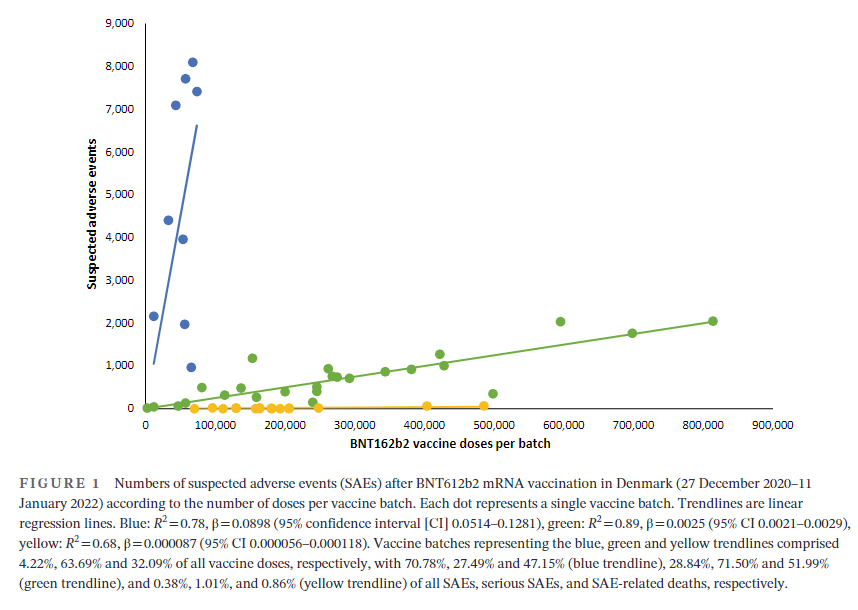
Excerpt:
Vaccination has been widely implemented for mitigation of coronavirus disease-2019 (Covid-19), and by 11 November 2022, 701 million doses of the BNT162b2 mRNA vaccine (Pfizer-BioNTech) had been administered and linked with 971,021 reports of suspected adverse effects (SAEs) in the European Union/European Economic Area (EU/EEA).1 Vaccine vials with individual doses are supplied in batches with stringent quality control to ensure batch and dose uniformity.2 Clinical data on individual vaccine batch levels have not been reported and batch-dependent variation in the clinical efficacy and safety of authorized vaccines would appear to be highly unlikely. However, not least in view of the emergency use market authorization and rapid implementation of large-scale vaccination programs, the possibility of batch-dependent variation appears worthy of investigation. We therefore examined rates of SAEs between different BNT162b2 vaccine batches administered in Denmark (population 5.8 million) from 27 December 2020 to 11 January 2022.
….
A total of 7,835,280 doses were administered to 3,748,215 persons with the use of 52 different BNT162b2 vaccine batches (2340–814,320 doses per batch) and 43,496 SAEs were registered in 13,635 persons, equaling 3.19 ± 0.03 (mean ± SEM) SAEs per person. In each person, individual SAEs were associated with vaccine doses from 1.531 ± 0.004 batches resulting in a total of 66,587 SAEs distributed between the 52 batches. Batch labels were incompletely registered or missing for 7.11% of SAEs, leaving 61,847 batch-identifiable SAEs for further analysis of which 14,509 (23.5%) were classified as severe SAEs and 579 (0.9%) were SAE-related deaths. Unexpectedly, rates of SAEs per 1000 doses varied considerably between vaccine batches with 2.32 (0.09–3.59) (median [interquartile range]) SAEs per 1000 doses, and significant heterogeneity (p < .0001) was observed in the relationship between numbers of SAEs per 1000 doses and numbers of doses in the individual batches. Three predominant trendlines were discerned, with noticeable lower SAE rates in larger vaccine batches and additional batch-dependent heterogeneity in the distribution of SAE seriousness between the batches representing the three trendlines (Figure 1). Compared to the rates of all SAEs, serious SAEs and SAE-related deaths per 1.000 doses were much less frequent and numbers of these SAEs per 1000 doses displayed considerably greater variability between batches, with lesser separation between the three trendlines (not shown).
Author(s): Max Schmeling, Vibeke Manniche, Peter Riis Hansen
Publication Date: 30 Mar 2023
Publication Site: European Journal of Clinical Investigation
