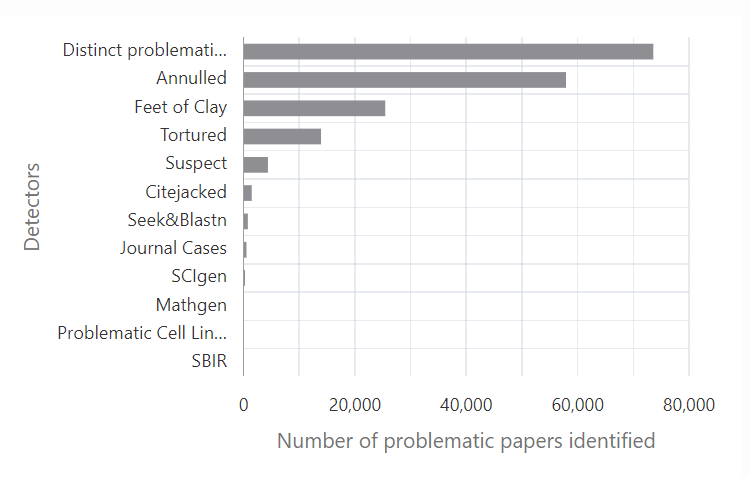
Link: https://www.wsj.com/us-news/education/harvard-investigation-francesa-gino-documents-9e334ffe
Excerpt:
A Harvard University probe into prominent researcher Francesca Gino found that her work contained manipulated data and recommended that she be fired, according to a voluminous court filing that offers a rare behind-the-scenes look at research misconduct investigations.
It is a key document at the center of a continuing legal fight involving Gino, a behavioral scientist who in August sued the university and a trio of data bloggers for $25 million.
The case has captivated researchers and the public alike as Gino, known for her research into the reasons people lie and cheat, has defended herself against allegations that her work contains falsified data.
The investigative report had remained secret until this week, when the judge in the case granted Harvard’s request to file the document, with some personal details redacted, as an exhibit.
….
An initial inquiry conducted by two HBS faculty included an examination of the data sets from Gino’s computers and records, and her written responses to the allegations. The faculty members concluded that a full investigation was warranted, and Datar agreed.
In the course of the full investigation, the two faculty who ran the initial inquiry plus a third HBS faculty member interviewed Gino and witnesses who worked with her or co-wrote the papers. They gathered documents including data files, correspondence and various drafts of the submitted manuscripts. And they commissioned an outside firm to conduct a forensic analysis of the data files.
The committee concluded that in the various studies, Gino edited observations in ways that made the results fit hypotheses.
When asked by the committee about work culture at the lab, several witnesses said they didn’t feel pressured to obtain results. “I never had any indication that she was pressuring people to get results. And she never pressured me to get results,” one witness said.
Author(s): Nidhi Subbaraman
Publication Date: 14 March 2024
Publication Site: WSJ