Link: https://www2.deloitte.com/us/en/insights/deloitte-review/issue-21/analytics-bad-data-quality.html
Graphic:
Excerpt:
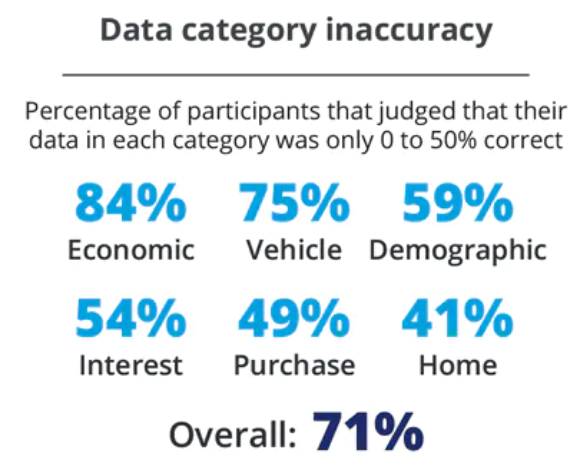
More than two-thirds of survey respondents stated that the third-party data about them was only 0 to 50 percent correct as a whole. One-third of respondents perceived the information to be 0 to 25 percent correct.
Whether individuals were born in the United States tended to determine whether they were able to locate their data within the data broker’s portal. Of those not born in the United States, 33 percent could not locate their data; conversely, of those born in the United States, only 5 percent had missing information. Further, no respondents born outside the United States and residing in the country for less than three years could locate their data.
The type of data on individuals that was most available was demographic information; the least available was home data. However, even if demographic information was available, it was not all that accurate and was often incomplete, with 59 percent of respondents judging their demographic data to be only 0 to 50 percent correct. Even seemingly easily available data types (such as date of birth, marital status, and number of adults in the household) had wide variances in accuracy.
Author(s): John Lucker, Susan K. Hogan, Trevor Bischoff
Publication Date: 31 July 2017
Publication Site: Deloitte