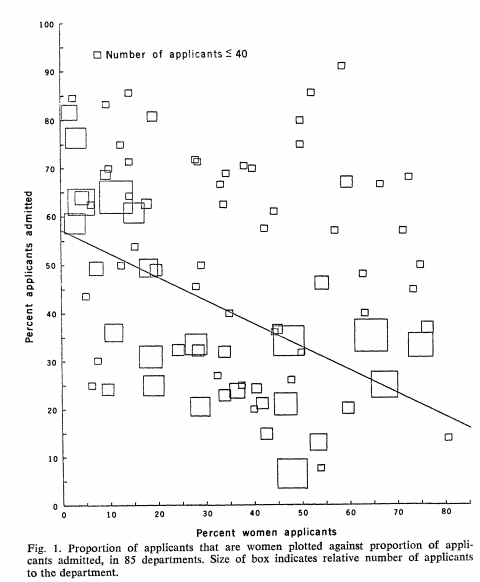
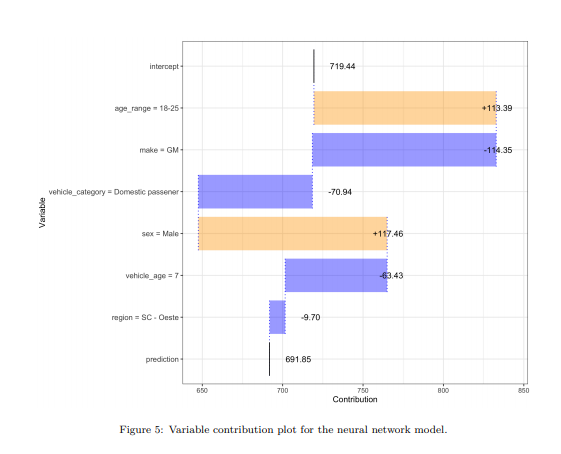
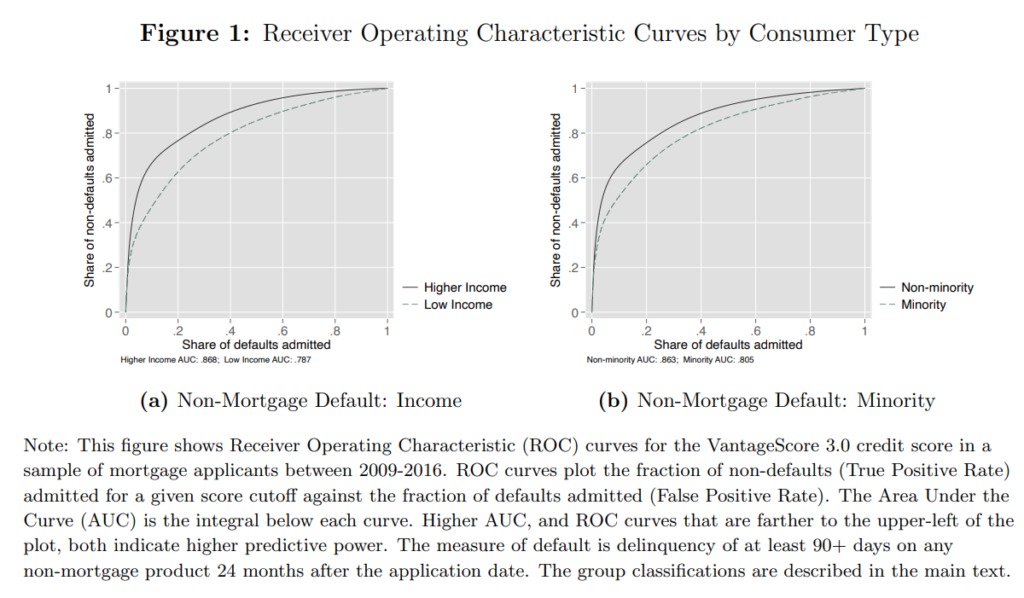
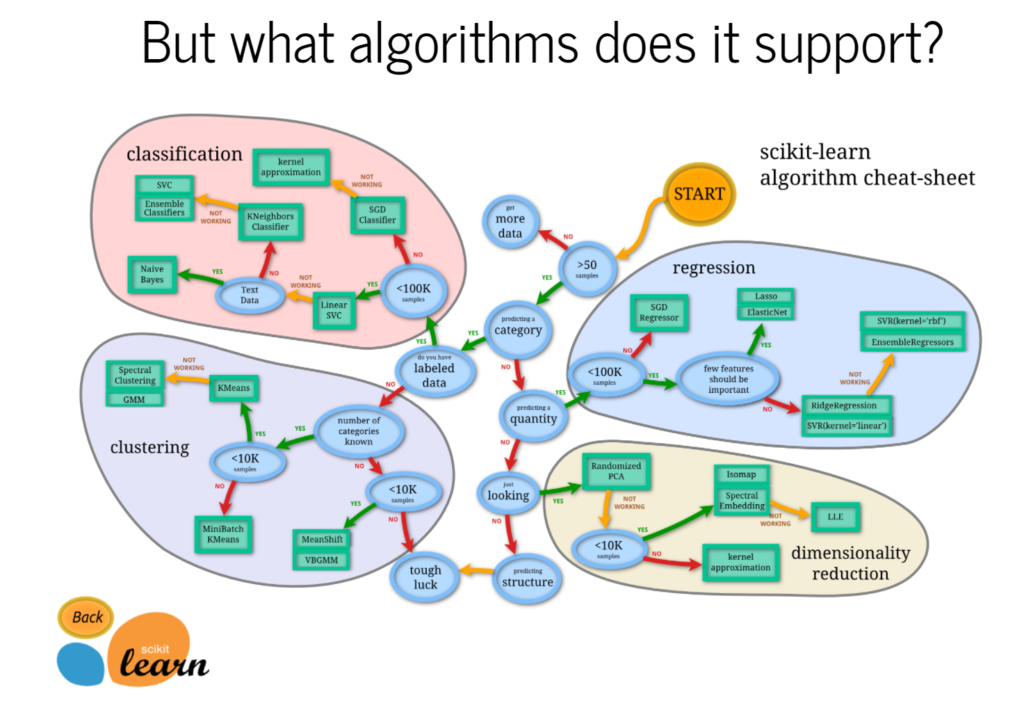
Link: https://www.nationalreview.com/2021/05/rebekah-jones-the-covid-whistleblower-who-wasnt/
Excerpt:
There is an extremely good reason that nobody in the Florida Department of Health has sided with Jones. It’s the same reason that there has been no devastating New York Times exposé about Florida’s “real” numbers. That reason? There is simply no story here. By all accounts, Rebekah Jones is a talented developer of GIS dashboards. But that’s all she is. She’s not a data scientist. She’s not an epidemiologist. She’s not a doctor. She didn’t “build” the “data system,” as she now claims, nor is she a “data manager.” Her role at the FDOH was to serve as one of the people who export other people’s work—from sets over which she had no control—and to present it nicely on the state’s dashboard. To understand just how far removed Jones really is from the actual data, consider that even now—even as she rakes in cash from the gullible to support her own independent dashboard—she is using precisely the same FDOH data used by everyone else in the world. Yes, you read that right: Jones’s “rebel” dashboard is hooked up directly to the same FDOH that she pretends daily is engaged in a conspiracy. As Jones herself confirmed on Twitter: “I use DOH’s data. If you access the data from both sources, you’ll see that it is identical.” She just displays them differently.
Or, to put it more bluntly, she displays them badly. When you get past all of the nonsense, what Jones is ultimately saying is that the State of Florida—and, by extension, the Centers for Disease Control and Prevention—has not processed its data in the same way that she would if she were in charge. But, frankly, why would it? Again, Jones isn’t an epidemiologist, and her objections, while compelling to the sort of low-information political obsessive she is so good at attracting, betray a considerable ignorance of the material issues. In order to increase the numbers in Florida’s case count, Jones counts positive antibody tests as cases. But that’s unsound, given that (a) those positives include people who have already had COVID-19 or who have had the vaccine, and (b) Jones is unable to avoid double-counting people who have taken both an antibody test and a COVID test that came back positive, because the state correctly refuses to publish the names of the people who have taken those tests. Likewise, Jones claims that Florida is hiding deaths because it does not include nonresidents in its headline numbers. But Florida does report nonresident deaths; it just reports them separately, as every state does, and as the CDC’s guidelines demand. Jones’s most recent claim is that Florida’s “excess death” number is suspicious. But that, too, has been rigorously debunked by pretty much everyone who understands what “excess deaths” means in an epidemiological context—including by the CDC; by Daniel Weinberger, an epidemiologist at the Yale School of Public Health; by Lauren Rossen, a statistician at the CDC’s National Center for Health Statistics; and, most notably, by Jason Salemi, an epidemiologist at the University of South Florida, who, having gone to the trouble of making a video explaining calmly why the talking point was false, was then bullied off Twitter by Jones and her followers.
Author(s): Charles C. W. Cooke
Publication Date: 13 May 2021
Publication Site: National Review