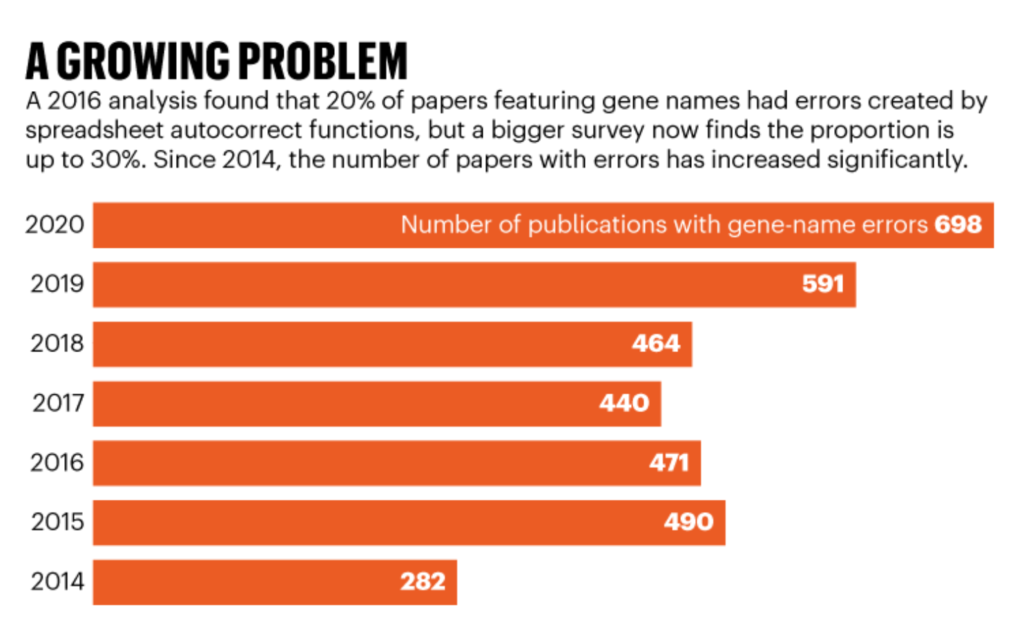
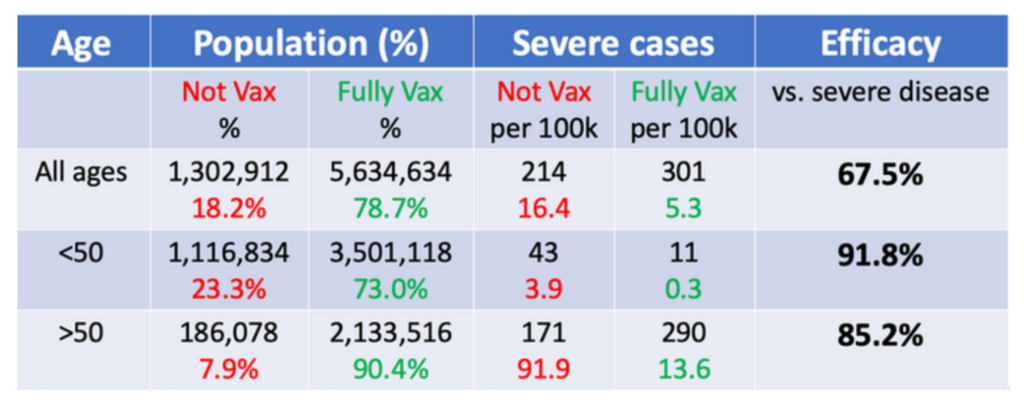
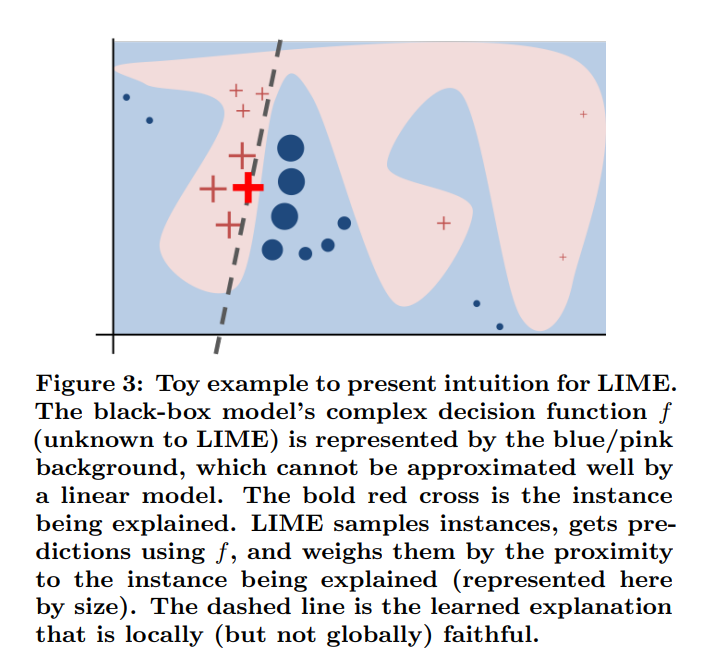
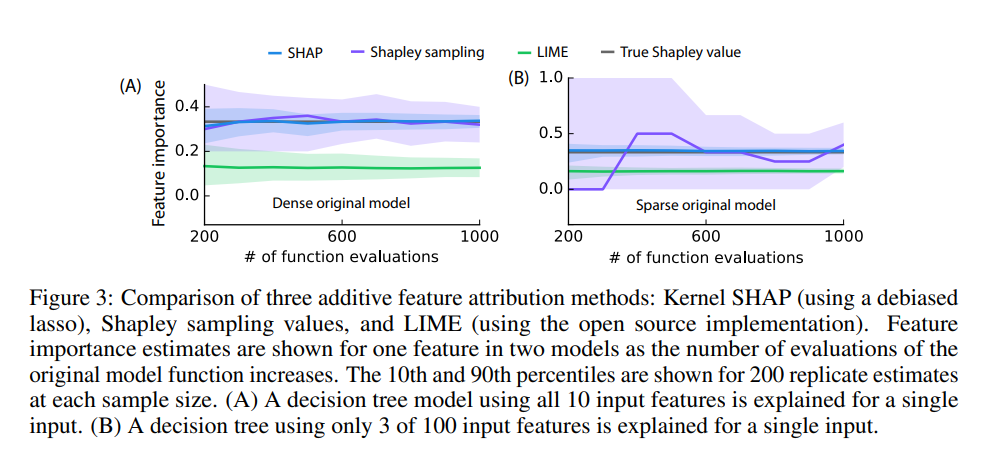
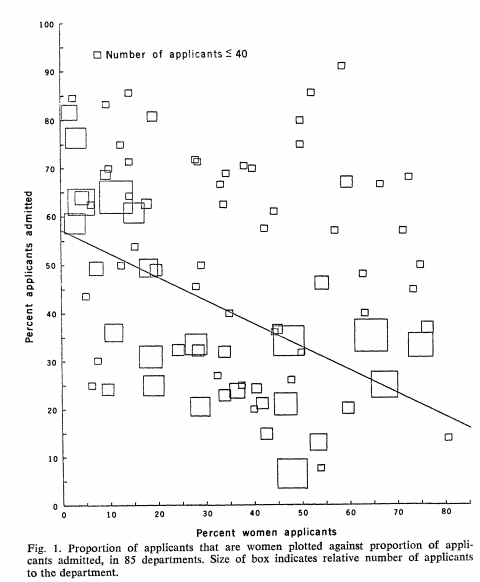
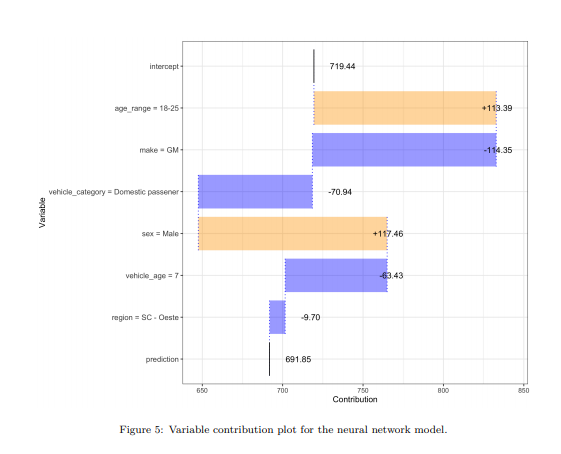
Link: https://eml.berkeley.edu//~crwalters/papers/randres.pdf
Graphic:
Abstract:
We study the results of a massive nationwide correspondence experiment sending more than
83,000 fictitious applications with randomized characteristics to geographically dispersed jobs
posted by 108 of the largest U.S. employers. Distinctively Black names reduce the probability of
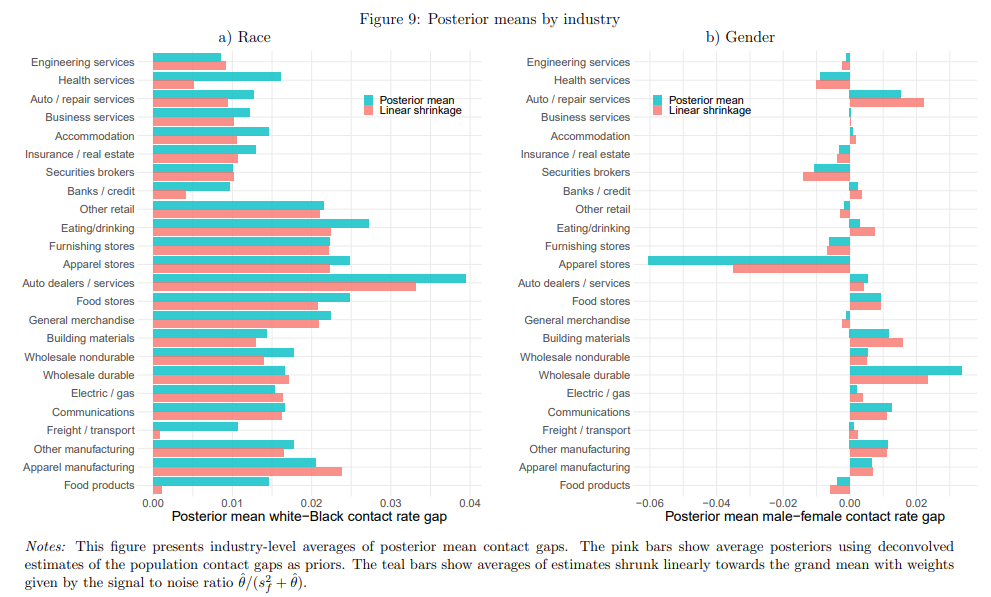
employer contact by 2.1 percentage points relative to distinctively white names. The magnitude
of this racial gap in contact rates differs substantially across firms, exhibiting a between-company
standard deviation of 1.9 percentage points. Despite an insignificant average gap in contact rates
between male and female applicants, we find a between-company standard deviation in gender
contact gaps of 2.7 percentage points, revealing that some firms favor male applicants while
others favor women. Company-specific racial contact gaps are temporally and spatially persistent,
and negatively correlated with firm profitability, federal contractor status, and a measure of
recruiting centralization. Discrimination exhibits little geographical dispersion, but two digit
industry explains roughly half of the cross-firm variation in both racial and gender contact gaps.
Contact gaps are highly concentrated in particular companies, with firms in the top quintile of
racial discrimination responsible for nearly half of lost contacts to Black applicants in the
experiment. Controlling false discovery rates to the 5% level, 23 individual companies are found
to discriminate against Black applicants. Our findings establish that systemic illegal
discrimination is concentrated among a select set of large employers, many of which can be
identified with high confidence using large scale inference methods.
Author(s): Patrick M. Kline, Evan K. Rose, and Christopher R. Walters
Publication Date: July 2021, Revised August 2021
Publication Site: NBER Working Papers, also Christopher R. Walters’s own webpages