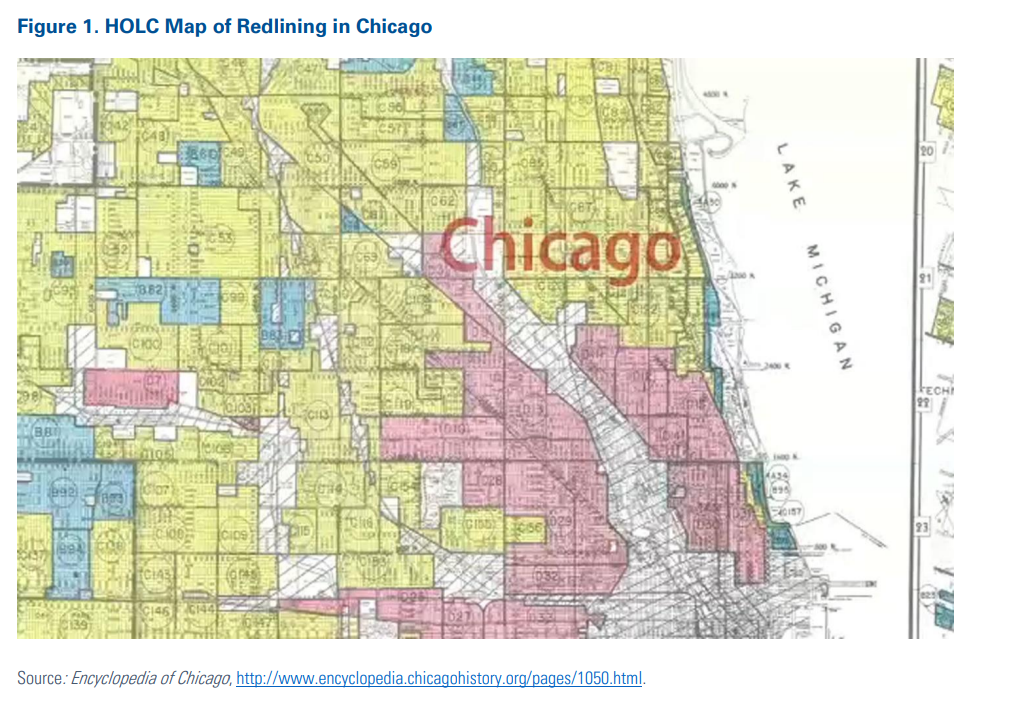
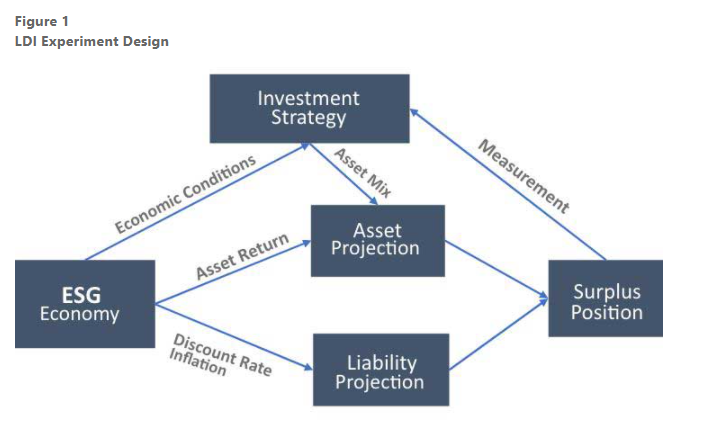
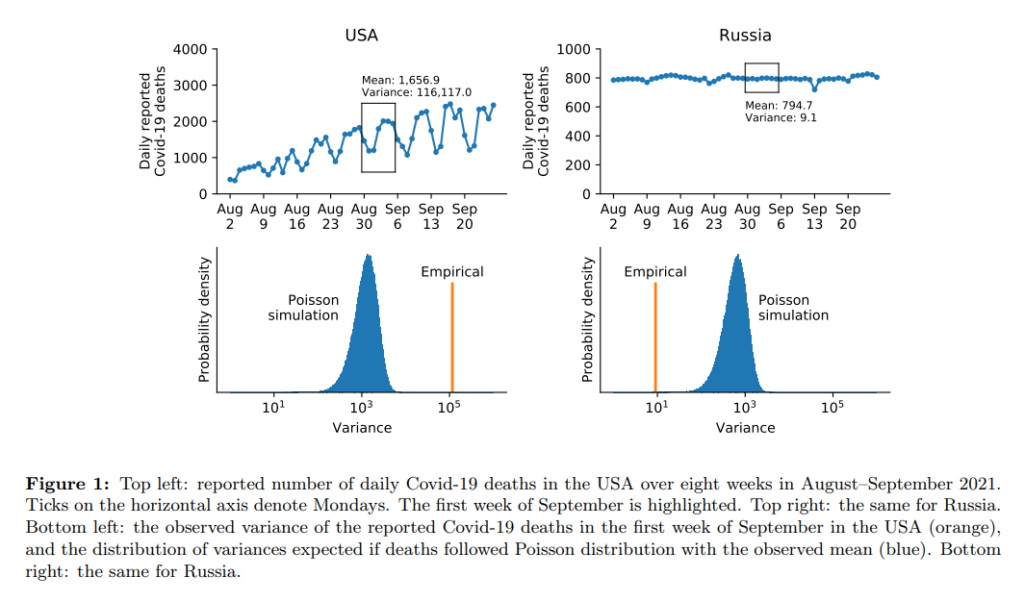
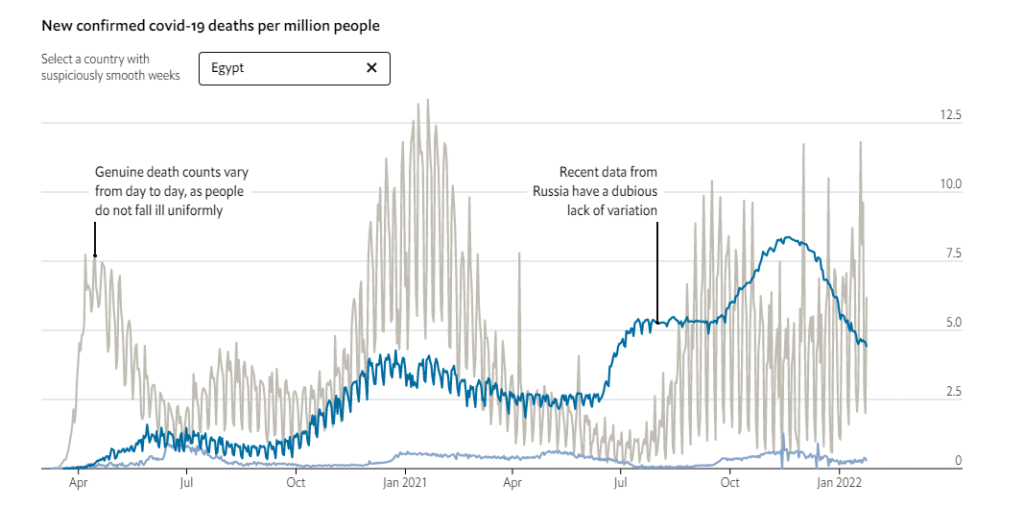
Graphic:
Excerpt:
This research paper is designed to introduce various terms used in defining
discrimination by stakeholders in the insurance industry (regulators, consumer
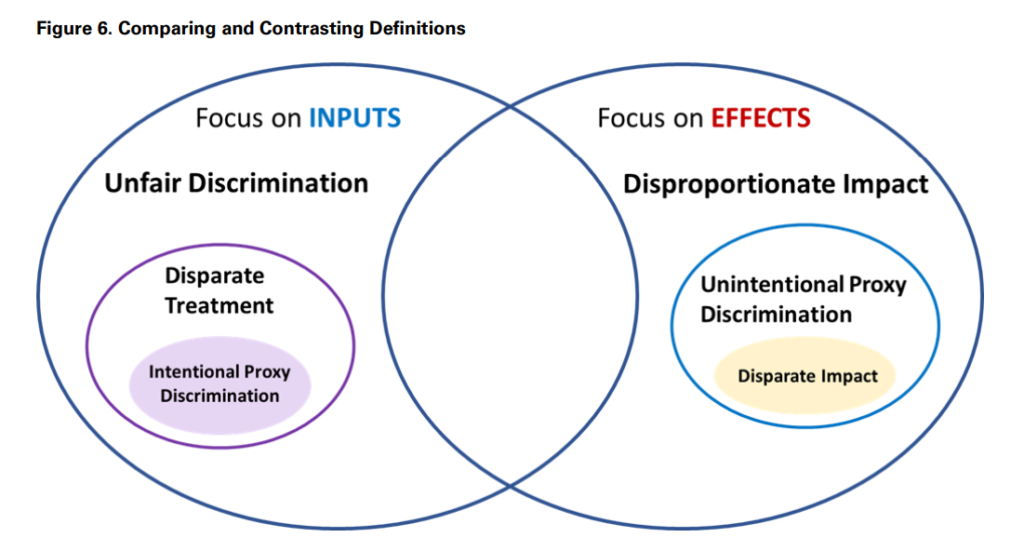
advocacy groups, actuaries and insurers, etc.). The paper defines protected class,
unfair discrimination, proxy discrimination, disproportionate impact, disparate
treatment and disparate impact.
Stakeholders are not always consistent in their definitions of these terms, and
these inconsistencies are highlighted and illustrated in this paper. It is essential to
elucidate key elements and attributes of certain terms as well as conflicting
approaches to defining discrimination in insurance in order to move the industry
discussion forward.
While this paper does not make a judgment on the appropriateness of the
definitions put forth, nor does it promulgate what the definitions should be,
readers will be empowered to understand the components of discrimination terms
used in insurance, as well as be introduced to the potential implications for
insurers.
Actuaries who have a strong foundational knowledge of these terms are likely to
play a key role in informing those who define and refine these terms for insurance
purposes in the future. This paper is not a legal review, and thus discusses terms
and concepts as they are used by insurance stakeholders, rather than what their
ultimate legal definition will be. However, it is important for actuaries to
understand the point of view of various stakeholders, and the potential impact it
could have on actuarial work. As the regulatory and legislative landscape
continues to shift, this brief should be considered a living document, that will
periodically require update.
Author(s): Kudakwashe F. Chibanda, FCAS
Publication Date: March 2022
Publication Site: CAS