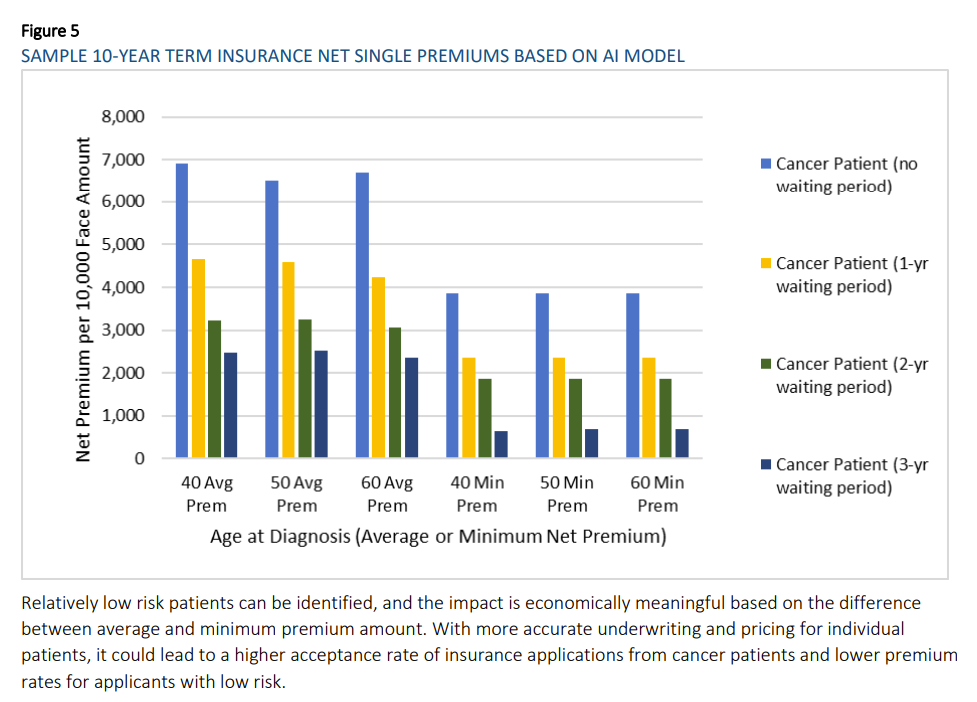
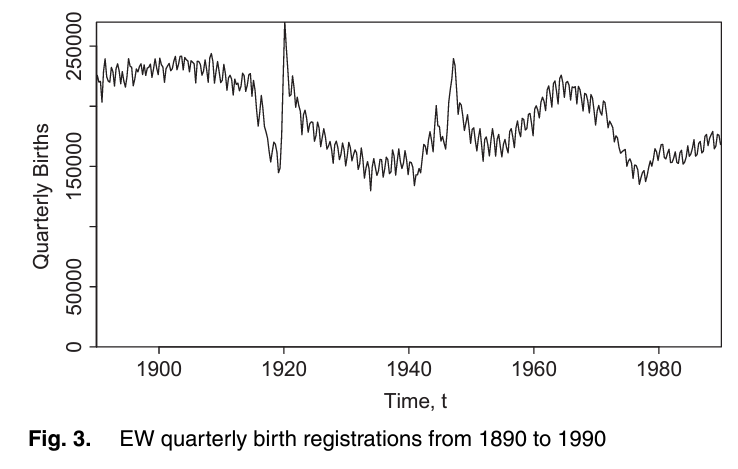
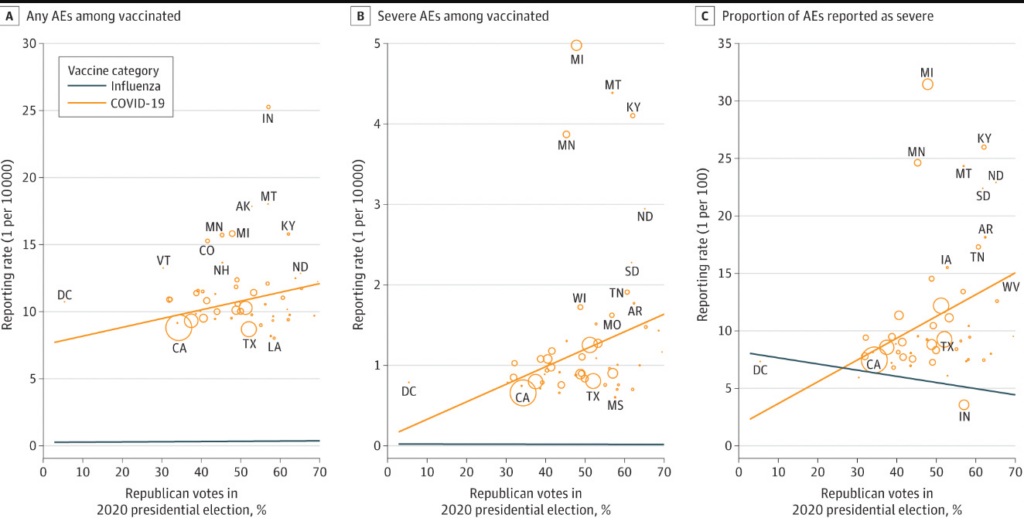
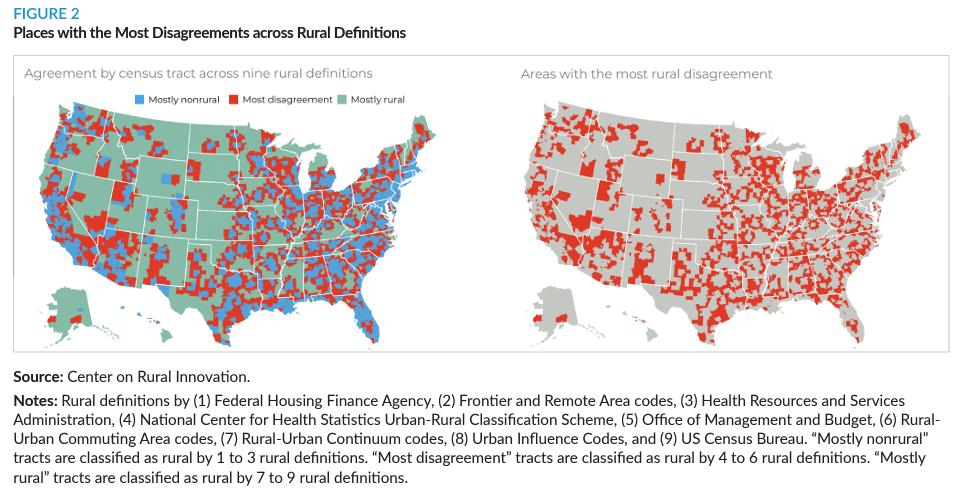
Link: https://www.federalregister.gov/documents/2024/06/12/2024-12336/request-for-information-on-uses-opportunities-and-risks-of-artificial-intelligence-in-the-financial
Excerpt:
SUMMARY:
The U.S. Department of the Treasury (Treasury) is seeking comment through this request for information (RFI) on the uses, opportunities and risks presented by developments and applications of artificial intelligence (AI) within the financial sector. Treasury is interested in gathering information from a broad set of stakeholders in the financial services ecosystem, including those providing, facilitating, and receiving financial products and services, as well as consumer and small business advocates, academics, nonprofits, and others.
DATES:
Written comments and information are requested on or before August 12, 2024.
….
Oversight of AI—Explainability and Bias
The rapid development of emerging AI technologies has created challenges for financial institutions in the oversight of AI. Financial institutions may have an incomplete understanding of where the data used to train certain AI models and tools was acquired and what the data contains, as well as how the algorithms or structures are developed for those AI models and tools. For instance, machine-learning algorithms that internalize data based on relationships that are not easily mapped and understood by financial institution users create questions and concerns regarding explainability, which could lead to difficulty in assessing the conceptual soundness of such AI models and tools.[22]
Financial regulators have issued guidance on model risk management principles, encouraging financial institutions to effectively identify and mitigate risks associated with model development, model use, model validation (including validation of vendor and third-party models), ongoing monitoring, outcome analysis, and model governance and controls.[23] These principles are technology-agnostic but may not be applicable to certain AI models and tools. Due to their inherent complexity, however, AI models and tools may exacerbate certain risks that may warrant further scrutiny and risk mitigation measures. This is particularly true in relation to the use of emerging AI technologies.
Furthermore, the rapid development of emerging AI technologies may create a human capital shortage in financial institutions, where sufficient knowledge about a potential risk or bias of those AI technologies may be lacking such that staff may not be able to effectively manage the development, validation, and application of those AI technologies. Some financial institutions may rely on third-party providers to develop and validate AI models and tools, which may also create challenges in ensuring alignment with relevant risk management guidance.
Challenges in explaining AI-assisted or AI-generated decisions also create questions about transparency generally, and raise concerns about the potential obfuscation of model bias that can negatively affect impacted entities. In the Non-Bank Report, Treasury noted the potential for AI models to perpetuate discrimination by utilizing and learning from data that reflect and reinforce historical biases.[24] These challenges of managing explainability and bias may impede the adoption and use of AI by financial institutions.
Author(s): Department of the Treasury.
Publication Date: 6/12/2024
Publication Site: Federal Register