The CDC recommended that fully vaccinated people begin wearing masks indoors again in places with high Covid transmission rates.
The updated guidance comes ahead of the fall, when the delta variant is expected to cause another surge in new coronavirus cases and many large employers plan to bring workers back to the office.
Experts say Covid prevention strategies remain critical to protect people from the virus, especially in areas of moderate-to-high community transmission levels.
Author(s): Berkeley Lovelace Jr., Meg Tirrell, Associated Press
The general assembly therefore declares that in order to ensure that all Colorado residents have fair and equitable access to insurance products, it is necessary to: (a) Prohibit: (I) Unfair discrimination based on race, color, national or ethnic origin, religion, sex, sexual orientation, disability, gender identity, or gender expression in any insurance practice; and (II) The use of external consumer data and information sources, as well as algorithms and predictive models using external consumer data and information sources, which use has the result of unfairly discriminating based on race, color, national or ethnic origin, religion, sex, sexual orientation, disability, gender identity, or gender expression; and (b) After notice and rule-making by the commissioner of insurance, require insurers that use external consumer data and information sources, algorithms, and predictive models to control for, or otherwise demonstrate that such use does not result in, unfair discrimination.
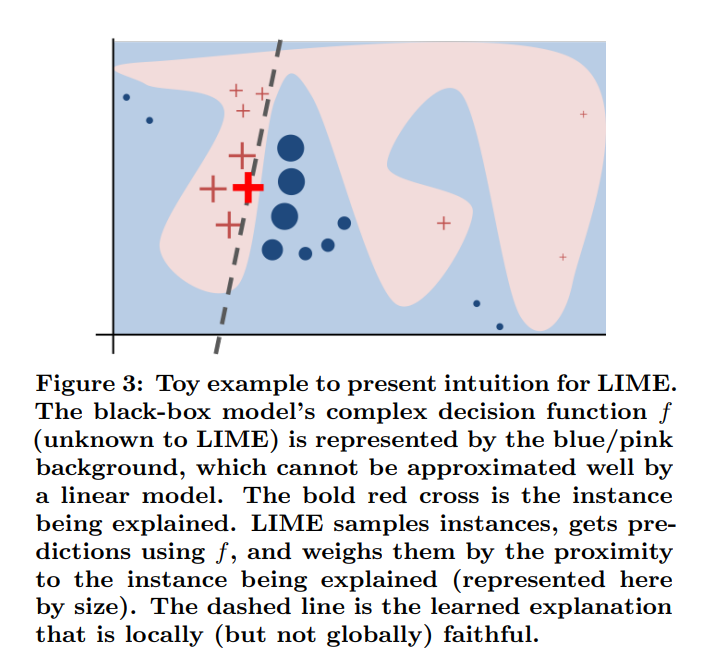
Despite widespread adoption, machine learning models remain mostly black boxes. Understanding the reasons behind predictions is, however, quite important in assessing trust, which is fundamental if one plans to take action based on a prediction, or when choosing whether to deploy a new model. Such understanding also provides insights into the model, which can be used to transform an untrustworthy model or prediction into a trustworthy one. In this work, we propose LIME, a novel explanation technique that explains the predictions of any classifier in an interpretable and faithful manner, by learning an interpretable model locally around the prediction. We also propose a method to explain models by presenting representative individual predictions and their explanations in a non-redundant way, framing the task as a submodular optimization problem. We demonstrate the flexibility of these methods by explaining different models for text (e.g. random forests) and image classification (e.g. neural networks). We show the utility of explanations via novel experiments, both simulated and with human subjects, on various scenarios that require trust: deciding if one should trust a prediction, choosing between models, improving an untrustworthy classifier, and identifying why a classifier should not be trusted.
Author(s): Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin
Publication Date: 2016
Publication Site: kdd, Association for Computing Machinery
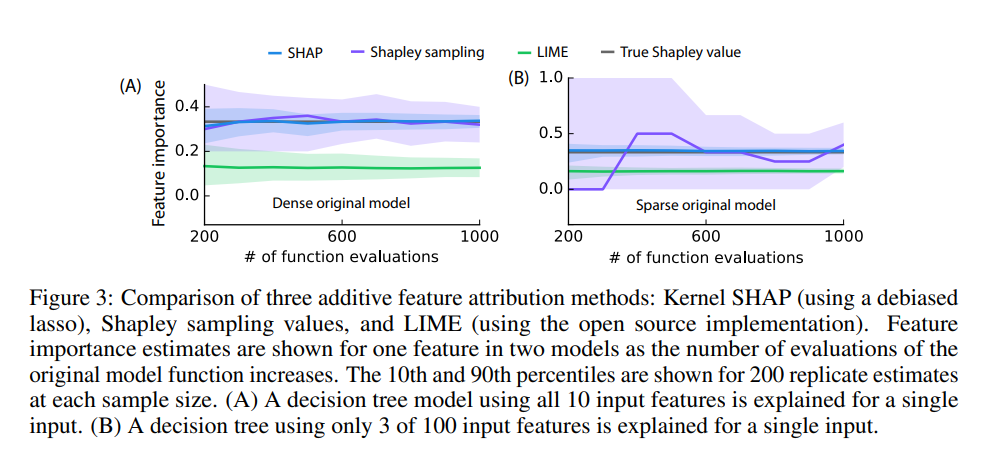
Understanding why a model makes a certain prediction can be as crucial as the prediction’s accuracy in many applications. However, the highest accuracy for large modern datasets is often achieved by complex models that even experts struggle to interpret, such as ensemble or deep learning models, creating a tension between accuracy and interpretability. In response, various methods have recently been proposed to help users interpret the predictions of complex models, but it is often unclear how these methods are related and when one method is preferable over another. To address this problem, we present a unified framework for interpreting predictions, SHAP (SHapley Additive exPlanations). SHAP assigns each feature an importance value for a particular prediction. Its novel components include: (1) the identification of a new class of additive feature importance measures, and (2) theoretical results showing there is a unique solution in this class with a set of desirable properties. The new class unifies six existing methods, notable because several recent methods in the class lack the proposed desirable properties. Based on insights from this unification, we present new methods that show improved computational performance and/or better consistency with human intuition than previous approaches.
Author(s): Scott M. Lundberg, Su-In Lee
Publication Date: 2017
Publication Site: Conference on Neural Information Processing Systems
Machine learning has great potential for improving products, processes and research. But computers usually do not explain their predictions which is a barrier to the adoption of machine learning. This book is about making machine learning models and their decisions interpretable.
After exploring the concepts of interpretability, you will learn about simple, interpretable models such as decision trees, decision rules and linear regression. Later chapters focus on general model-agnostic methods for interpreting black box models like feature importance and accumulated local effects and explaining individual predictions with Shapley values and LIME.
All interpretation methods are explained in depth and discussed critically. How do they work under the hood? What are their strengths and weaknesses? How can their outputs be interpreted? This book will enable you to select and correctly apply the interpretation method that is most suitable for your machine learning project.
In machine learning, there has been a trade-off between model complexity and model performance. Complex machine learning models e.g. deep learning (that perform better than interpretable models e.g. linear regression) have been treated as black boxes. Research paper by Ribiero et al (2016) titled “Why Should I Trust You” aptly encapsulates the issue with ML black boxes. Model interpretability is a growing field of research. Please read here for the importance of machine interpretability. This blog discusses the idea behind LIME and SHAP.
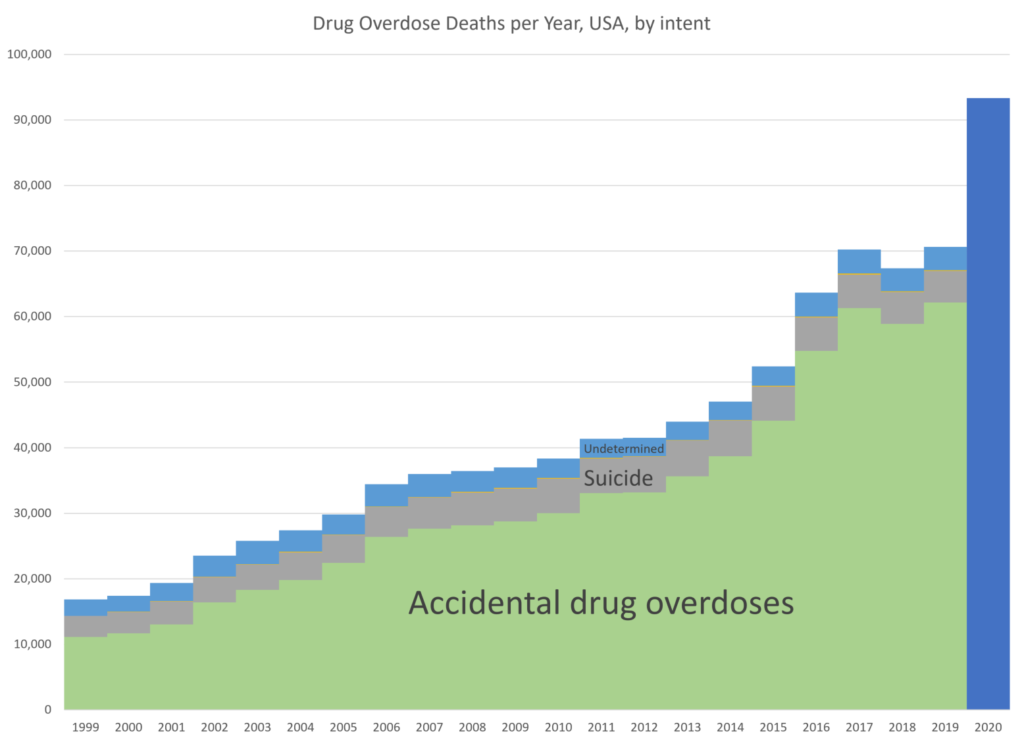
In 2020, there were over 93K deaths due to drug overdoses — a 30% increase over 2019.
This is super-bad, and worse than what I have seen for increases in other causes of death. I knew it was going to be bad, but I didn’t realize it was going to be this bad.
Not all 10% increases are created equal. And by that we mean, assumption effects are often more impactful in one direction than in the other. Especially when it comes to truncation models or those which use a CTE measure (conditional tail expectation).
Principles-based reserves, for example, use a CTE70 measure. [Take the average of the (100% – 70% = 30%) of the scenarios.] If your model increases expense 3% across the board, sure, on average, your asset funding need might increase by exactly that amount. However, because your final measurement isn’t the average across all the scenarios, but only the worst ones, it’s likely that your reserve amounts are going to increase by significantly more than the average. You might need to run a few different tests, at various magnitudes of change, to determine how your various outputs change as a function of the volatility of your inputs.
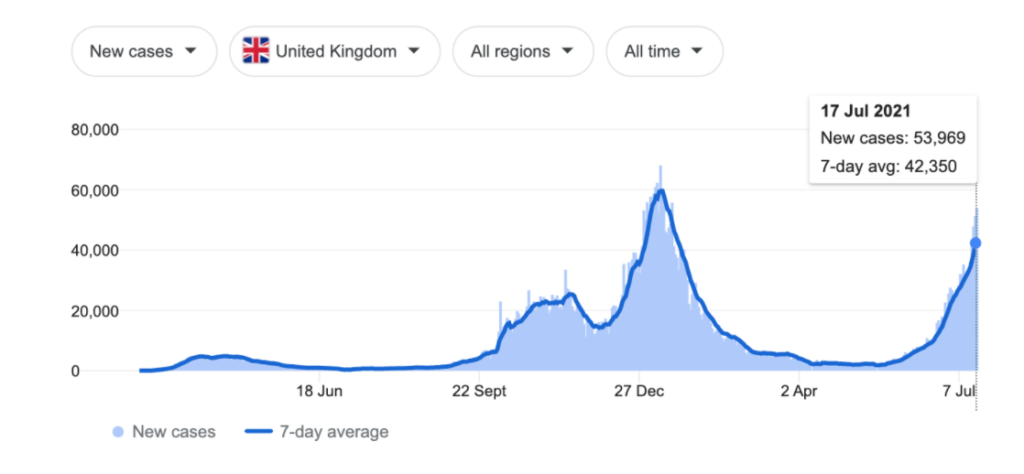
On Monday, July 19, the country is ditching all of its remaining pandemic-related restrictions. People will be able to go to nightclubs, or gather in groups as large as they like. They will not be legally compelled to wear masks at all, and can stop social distancing. The government, with an eye on media coverage, has dubbed it “Freedom Day,” and said the lifting of safety measures will be irreversible.
At the same time, coronavirus cases are rapidly rising in the UK. It recorded over 50,000 new cases on Friday, and its health minister says that the daily figure of new infections could climb to over 100,000 over the summer.
…..
The UK’s vaccination program is still under way, but it has been broadly successful so far. In all, 68% of the adult population is fully vaccinated, and about 88% of adults have received their first dose (this includes the 68% who have had both doses). Just 6% of Brits are hesitant about getting a shot, according to the Office for National Statistics.
…..
But the government seems to be betting that not all numbers are equally scary. It hopes that hospitalizations will stay low enough to stop the National Health Service from being completely overwhelmed. It is making the assumption that the link between cases and hospitalization rates has been weakened, if not broken.
“This wave is very different to previous ones,” says Oliver Geffen Obregon, an epidemiologist based in the UK, who has worked with the World Health Organization. “The proportion of hospitalization is way lower compared to similar points on the epidemic curve before the vaccination program.”
The pandemic and the work-from-home environment it spawned also led many economists to speculate that workers would become better adapted to technology, more efficient and strike a healthier balance between work and life. This, in turn, would leave them more mobile. A Microsoft Corp. workplace trends survey found that 40% of Americans are considering leaving their jobs this year. And many are doing just that, with 2.5% of the employed quitting their jobs in May, according to the Bureau of Labor Statistics’ Job Opening and Labor Turnover Survey. Although that’s down from the record 2.8% in April, it’s still higher than any other point since at least before 2001. Plus, consider that the quit rate was only 2.3% in 2019 when unemployment was just 3.6%, compared with 5.8% this May.
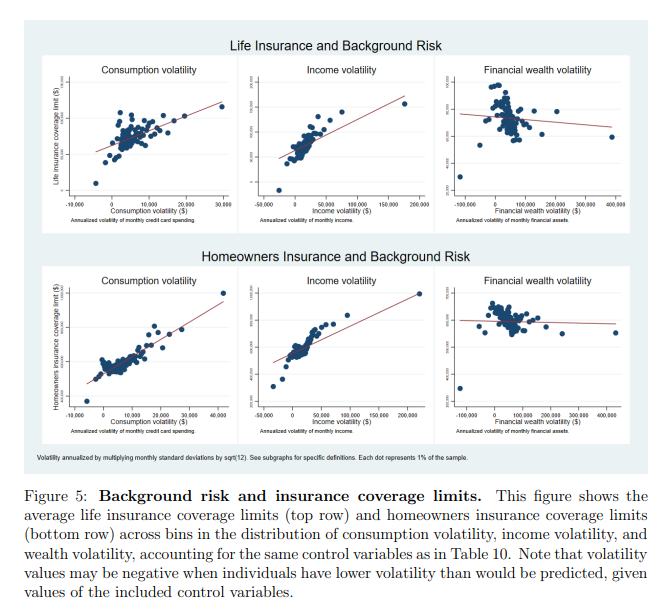
Theoretically, wealthier people should buy less insurance, and should self-insure through saving instead, as insurance entails monitoring costs. Here, we use administrative data for 63,000 individuals and, contrary to theory, find that the wealthier have better life and property insurance coverage. Wealth-related differences in background risk, legal risk, liquidity constraints, financial literacy, and pricing explain only a small fraction of the positive wealth-insurance correlation. This puzzling correlation persists in individual fixed-effects models estimated using 2,500,000 person-month observations. The fact that the less wealthy have less coverage, though intuitively they benefit more from insurance, might increase financial health disparities among households.